2022. 2. 25. 11:07ㆍProgramming/iOS_Swift
이 글은 약 5주간 진행했던 Service Level Project(이하 'SLP')를 회고 및 정리하기 위한 글이다. 이번 프로젝트를 진행하면서 새로운 시도를 많이 했는데 그 중 가장 큰 도전이었던 MVVM + Clean Architecture(클린 아키텍처) 적용에 대해서 정리하려고 한다.
목차는 다음과 같다. 1편에서는 3번까지만 다루겠다.
1. Clean Architecture(클린 아키텍처)란?
2. MVVM + Clean Architecture의 구성요소
3. 전반적인 Flow
4. Dependency(의존성)와 Dependency Inversion(의존성 역전)
5. SLP에 왜 Clean Architecture를 적용하였는지?
6. Clean Architecture 적용 후기 및 회고
1. Clean Architecture(클린 아키텍처)란?
우선 '클린 아키텍처'가 대체 무엇인지부터 짚고 넘어가야할 것 같다. 클린 아키텍처라는 패턴의 최초 시작부터 살펴보면, 해당 패턴 자체는 꽤 예전에 나온 개념이다.(2012년도에 Robert C. Martin씨가 설계했다. https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html) 그러나 iOS의 아키텍처 패턴으로 클린 아키텍처가 적용된 것은 비교적 최근이다. 2019년도에 Oleh씨가 MVVM과 클린아키텍처를 같이 사용하게되면서 iOS의 아키텍처 패턴 중 하나로 보편화 되게 된다.
GitHub - kudoleh/iOS-Clean-Architecture-MVVM: Template iOS app using Clean Architecture and MVVM. Includes DIContainer, FlowCoor
Template iOS app using Clean Architecture and MVVM. Includes DIContainer, FlowCoordinator, DTO, Response Caching and one of the views in SwiftUI - GitHub - kudoleh/iOS-Clean-Architecture-MVVM: Tem...
github.com
2012년도에 로버트씨는 클린아키텍처에 대해 다음과 같이 소개했다.
클린 아키텍처를 사용하면, 소프트웨어 개발의 구조와 계층을 분리하여 효율적인 프로그램 구현이 가능할 것입니다.
즉 쉽게 정리하면 클린 아키텍처가 무엇이냐고 했을 때, 클린 아키텍처는 어떤 소프트웨어 개발의 구조와 계층을 역할에 따라 분리함으로써 사용자가 시스템을 보다 쉽게 이해하고 유지보수를 간편하게 만들어주는 아키텍처 패턴이라고 말할 수 있을 것 같다.
2. MVVM + Clean Architecture의 구성요소
간단하게 클린 아키텍처의 역사와 정의에 대해 살펴봤다. 그렇다면 해당 아키텍처 패턴이 어떻게 iOS에 적용되고 어떠한 구성요소를 가지고 있는지 구체적으로 살펴보자.
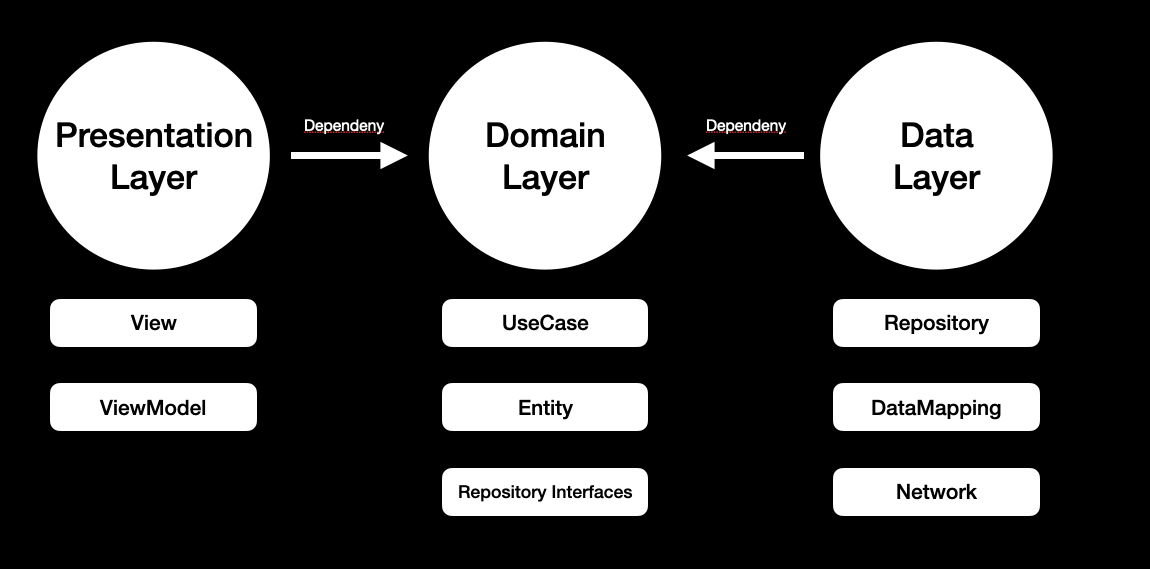
구성요소는 위와 같다. 큰 범주로 나누면 Presentation Layer, Domain Layer, Data Layer로 나눌 수 있다. 각 레이어들의 의존성 방향은 모두 Domain쪽으로 향한다. 그리고 각각의 레이어에는 세부 구성요소가 포함되어 있다.
사실 나는 처음 클린아키텍처를 학습할 때, 개발을 공부한 기간이 일천해서 뷰와 뷰모델, 네트워크 부분을 제외하고는 전부 각각이 무슨 역할을 하는지 하나도 몰랐다. 또 무슨 역할을 하는 건지 상세하게 적어둔 레퍼런스도 찾기 힘들었다. 그러다보니 그냥 무작정 예제 따라 만들면서 억지로 이해한 것 같다. 따라서, 나는 나와 같이 힘들게 공부하는 사람이 없길 바라는 마음에 모든 구성요소가 무슨 역할을 하는지 최대한 상세하고 이해하기 쉽게 적어보려고 한다.
Presentaion Layer
프레젠테이션 레이어는 기본적으로 뷰를 그리는 레이어이다. 즉 뷰를 그려주는 로직들이 모두 프레젠테이션 레이어에 포함된다고 보면 된다. 그렇다면 기존의 MVC나 MVVM에서 뷰컨트롤러와 뷰모델이 가지는 역할과 클린아키텍처에서 뷰컨트롤러와 뷰모델의 역할 차이가 무엇인지에 대해 궁금할 수 있다. 가장 큰 차이점은 비즈니스 로직의 유무이다.
비즈니스 로직이란?
비즈니스 로직은 사실 좀 모호한 개념이고 명확한 기준이 없다. 사람들마다 어떤 것을 비즈니스 로직으로 보는지 조금씩 다르기 때문이다. 명확한 기준은 없지만 크게 봤을 때, 구분할 수 있는 방법은 있다. 다음은 비즈니스 로직을 이해하기 위한 한 예시이다.
당신이 만약 은행에서 다른 누군가에게 송금을 한다고 가정해보자.
먼저, 당신이 알고 있어야할 내용들은 뭘까?
1. 당신의 신원(신분증 등)이 필요할 것이다.
2. 얼마의 돈을 송금할지 알아야할 것이다.
3. 당신의 계좌번호와 상대의 계좌번호를 알아야할 것이다.
4. 계좌 비밀번호도 알아야할 것이다.
그러면 송금을 하는 과정에서 반드시 적용되어야만 하는 비즈니스 로직은 무엇일까.
1. 송금을 하는 사람이 송금을 할 자격이 되는지, 계좌에 돈은 충분한지 확인해야 한다.
2. 송금은 성공할지 실패할지 반드시 둘 중 하나여야 한다.(상대 계좌에 돈이 입금되거나 아예 송금이 안되거나 둘 중 하나. 중간에 돈이 갑자기 다른 계좌로 새거나 이런 경우가 없어야함)
3. 만약 송금하려 하는 돈이 일정 금액 이상이라면 정부에 보고해야할 수도 있다.
정리하면, 유저가 알고 있어야 하는 내용들은 input에 해당한다고 보면된다. 그리고 그 input을 받아서 처리하는 일련의 과정들이 모두 비즈니스 로직에 해당한다.
다시 본론으로 돌아와서, MVC패턴의 경우 비즈니스 로직, 뷰 관련 로직 등 모든 로직이 뷰컨트롤러에 포함되어 있다. MVVM 패턴의 경우, 비즈니스 로직과 뷰를 그려주는 로직을 뷰모델이 담당하고 있다. 반면 클린 아키텍처의 경우 뷰모델은 뷰를 그려주는 로직만 담당한다는 점에서 차이점이 있다. 그렇다면 분리된 비즈니스 로직은 어디에서 담당하고 있는지는 바로 다음 내용에서 알아보자.
Domain Layer
도메인 레이어는 모든 비즈니스 로직을 담당하는 계층으로 그 어느 계층에게도 의존하지 않는다는 특징을 가지고 있다. 도메인 레이어는 Entity(Business Model), UseCase 그리고 Repository Interfaces를 구성요소로 가지고 있다.
UseCase
유즈 케이스의 경우 비즈니스 로직을 직접적으로 담당하는 구성요소이다. 이후 설명하게될 레포지토리에서 받아온 응답값을 비즈니스 로직에 따라 처리하여 프레젠테이션 레이어쪽으로 넘겨주는 역할을 담당한다. 반대로 프레젠테이션 레이어에서 받은 입력값을 비즈니스 로직에 따라 처리해서 데이터 레이어쪽으로 넘겨주기도 한다. 예시를 통해 이해해보자.
import Foundation
final class ChatUseCase {
let repository: ChatRepositoryInterface
let firebaseRepository: FirebaseRepositoryInterface
init(repository: ChatRepositoryInterface, firebaseRepository: FirebaseRepositoryInterface) {
self.repository = repository
self.firebaseRepository = firebaseRepository
}
func postChat(parameter: [String: Any], otherUID: String, completion: @escaping (Result<ChatData, ChatError>) -> Void) {
repository.postChat(parameter: parameter, otherUID: otherUID) { [weak self] (result) in
switch result {
case let .success(data):
completion(.success(data))
case let .failure(error):
if error == .firebaseIdTokenExpired {
self?.firebaseRepository.refreshIDToken {
self?.repository.postChat(parameter: parameter, otherUID: otherUID, completion: { (result) in
switch result {
case let .success(data): completion(.success(data))
case let .failure(error): completion(.failure(error))
}
})
}
} else {
completion(.failure(error))
}
}
}
}
}이번 SLP에서 사용했던 코드를 들고 왔다. 코드가 좀 지저분하긴한데😅 간략하게 설명하면, 위의 유즈 케이스는 채팅을 입력하는 비즈니스 로직을 담당하고 있다. 레포지토리에서 받아온 응답값이 만약 파이어베이스 토큰만료라면 프레젠테이션 레이어로 넘기지 않고 바로 토큰 갱신 후 재요청을 해준다. 성공 응답값이나 실패 응답값이 왔다면 프레젠테이션 레이어로 넘겨주고 있다. 넘겨진 값이 성공이라면 프레젠테이션 레이어에서는 올바르게 채팅이 입력될 것이고 실패 응답값이라면 어떤 실패 응답값이냐에 따라서 토스트 메세지를 띄워줄 것이다.
Entity(Business Model)
엔티티는 MVC나 MVVM에서 사용하는 Model의 또다른 표현이라고 이해하면 편할 것 같다. 이후 설명하게될 DTO와 구분이 헷갈릴 수 있는데 가장 큰 차이점은 다음과 같다.
엔티티는 도메인 레이어에 속하기 때문에, 도메인 레이어의 원칙 중 하나인 프레젠테이션 레이어에서 사용하는 UIKit이나 데이터 레이어에서 사용하는 Codable처럼 다른 레이어에서 채택하는 것들을 사용해서는 안된다. 따라서 아래의 엔티티를 보면 Foundation 프레임워크를 제외하고 어떠한 것도 채택하고 있지 않음을 확인할 수 있다. 이는 유즈케이스에서도 동일하게 적용된다.
import Foundation
struct ChatData {
let toID: String
let fromID: String
let chatMessage: String
let createdAt: String
}Repository Interfaces
레포지토리 인터페이스란 도메인 레이어가 데이터 레이어에 의존하지 않고 레포지토리의 메서드들을 사용할 수 있게 만들어주는 프로토콜이다. 의존에 대해서 잘 이해가 안갈 수 있는데 이후 다른 카테고리에서 상세하게 다룰 예정이니 여기서는 가볍게 넘어가자. 레포지토리 인터페이스를 쉽게 이해하기 위해서는 하나의 예시를 통해 설명하면 좋을 것 같다. 팀원의 표현을 빌리자면, 레포지토리 인터페이스는 일종의 리모콘이라고 한다. 그림을 통해 보자.

대충 그려봤는데 요런 느낌일 것 같다. 그러면 여기서 드는 의문은 왜 레포지토리를 직접 참조하지 않고 굳이 레포지토리 인터페이스를 사용하는 등 돌아가는 길을 선택하냐일 것이다. 그 문제의 해답은 의존성 때문이다. 만약 도메인 레이어에서 데이터 레이어인 레포지토리를 직접 참조하게 되어버린다면 도메인 레이어는 데이터 레이어를 의존하게 되어 버린다. 그러면 클린 아키텍처의 원칙에 어긋나 버리게된다. 도메인 레이어는 절대적으로 독립적이어야 하고 그 어느 것도 의존해선 안되기 때문이다. 따라서 우리는 레포지토리 인터페이스라는 프로토콜을 활용함으로써 데이터 레이어에서 도메인 레이어를 의존하게 되는 의존성 역전(Dependency Inversion)을 일으킬 수 있다. 의존성과 의존성 역전에 대해서는 다시 또 상세하게 다룰 예정이다.
import Foundation
protocol ChatRepositoryInterface {
func postChat(parameter: [String: Any], otherUID: String, completion: @escaping (Result<ChatData, ChatError>) -> Void)
}
Data Layer
데이터 레이어는 가장 외부에 있는 계층 중의 하나로 데이터베이스나 외부 API와 관련된 데이터를 요청(Request)하고 또 받아오는(Response) 레이어이다. 데이터 레이어의 구성요소로는 Repository, DataMapping, Network로 구성되어 있다.
Repository
레포지토리란 데이터베이스나 외부 API로부터 데이터를 요청하고 받아오는 역할을 담당하는 구성요소이다. 아래의 코드를 보면 Moya라고 하는 라이브러리를 활용하여 외부 API로 채팅을 입력해줄 것을 요청하고 받아온 데이터를 가공하여 컴플레션으로 넘겨주고 있는 것을 확인할 수 있다.
import Foundation
import Moya
final class ChatRepository: ChatRepositoryInterface {
func postChat(parameter: [String: Any], otherUID: String, completion: @escaping (Result<ChatData, ChatError>) -> Void) {
let provider = MoyaProvider<SeSACFriendsAPI>()
provider.request(.postChat(parameter: parameter, otherUID: otherUID)) { result in
switch result {
case let .success(response):
let statusCode = response.statusCode
let statusCodeCheck = self.statusCodeCheck(statusCode: statusCode)
if let data = try? response.map(ChatResponseDTO.self).toDomain() {
if statusCodeCheck == nil {
completion(.success(data))
} else {
completion(.failure(statusCodeCheck!))
}
} else {
completion(.failure(statusCodeCheck!))
}
case let .failure(MoyaError):
let errorCode = MoyaError.errorCode
}
}
}
func statusCodeCheck(statusCode: Int) -> ChatError? {
switch statusCode {
case 200: return nil
case 201: return .cannotSendMessage
case 401: return .firebaseIdTokenExpired
case 406: return .notRegisteredUser
case 500: return .serverError
case 501: return .headerOrBodyError
default: return .serverError
}
}
}
DataMapping
데이터매핑은 우리가 레포지토리에서 요청해서 받은 JSON데이터 값들을 받아와서 사용자가 사용할 수 있게끔 구조체로 정렬해주는 역할을 수행한다. 이후 도메인에서 활용할 수 있도록 엔티티로 변환시켜준다. 이렇게 변환해주는 이유는 위의 엔티티부분에서 설명하였으므로 참고하면 좋을 것 같다.
import Foundation
struct ChatResponseDTO: Codable {
let id: String
let v: Int
let to, from, chat, createdAt: String
enum CodingKeys: String, CodingKey {
case id = "_id"
case v = "__v"
case to, from, chat, createdAt
}
}
extension ChatResponseDTO {
func toDomain() -> ChatData {
return .init(toID: to,
fromID: from,
chatMessage: chat,
createdAt: createdAt)
}
}
Network
네트워크는 우리가 자주 사용하는 외부 API와 Error등으로 이루어져 있다.

enum SeSACFriendsAPI {
// Auth
case loginToFriendsApp
case registerFriend(parameter: [String: Any])
// Home
case findSeSACAroundYou(parameter: [String: Any])
case requestFindFriends(parameter: [String: Any])
case suspendFindFriends
case checkMyQueueState
case hobbyRequest(parameter: [String: Any])
case hobbyAccept(parameter: [String: Any])
// Chat
case postChat(parameter: [String: Any], otherUID: String)
// Profile
case updateUserData(parameter: [String: Any])
case withdrawUser
}
extension SeSACFriendsAPI: TargetType {
...
}3. 전반적인 Flow
각 레이어들이 무슨 역할을 하는지 알았으니, 이제 전반적인 흐름에 대해서 그림으로 다뤄보려고 한다. 예를 들어, 유저의 채팅입력에 따라 어떤 로직을 거쳐서 어떤 응답값을 가져오는지 살펴보자.


앞서 설명했던 부분들을 한 눈에 보이게끔 그림으로 정리했다. 클린 아키텍처를 이해하는데에 많은 도움이 되었으면 좋겠다 ! 다음 편에서는 의존성과 의존성 역전 그리고 왜 이번 프로젝트에 클린 아키텍처를 적용했는지 다뤄보려고 한다.
'Programming > iOS_Swift' 카테고리의 다른 글
| [iOS_CS] COW(Copy On Write) 이해하기 (0) | 2022.03.06 |
|---|---|
| [iOS_Service Level Project(SLP)] Clean Architecture 적용기 (2) - Dependency, Clean Architecture 적용 이유에 대하여 (4) | 2022.02.28 |
| [iOS_Swift] Generic(1) - Generic Basic (0) | 2022.02.14 |
| [iOS_Swift] inout Parameter에 대하여 (0) | 2022.02.10 |
| [iOS_Swift] Properties - 지연 저장 프로퍼티(Lazy Stored Property) (0) | 2022.02.06 |